中国信通院“方升-全模态”大模型基准测试最新结果发布
过去一年,全模态大模型持续突破,实现语言、视觉、音频的统一建模与协同理解,成为人工智能走向通用智能的关键路径。然而,现有评测体系多聚焦于单模态或事实性描述任务,缺乏对跨模态因果推理、反事实想象、时间动态理解等深层认知能力的评测。为加快推动全模态大模型能力评估,中国信息通信研究院(以下简称“中国信通院”)研究推出了“方升-全模态”大模型基准测试体系,覆盖推理、生成及动态交互任务。近期,中国信通院组织完成了首期测试工作,最新体系和测试结果如下:
一、“方升-全模态”基准测试体系
全模态大模型评测体系构建遵循多维度、立体化原则:在数据构建层面,完善了从文本、图像、音频到长视频序列、3D 点云的全模态覆盖,并引入了模态复杂度、场景真实性、人工偏好及视频长度等多维度标注;在能力验证层面,构建了推理、生成及交互任务三大核心任务,覆盖反事实假设、时序因果、音视频协同、3D 渲染与动态交互等关键认知与应用能力。具体测试框架如下:
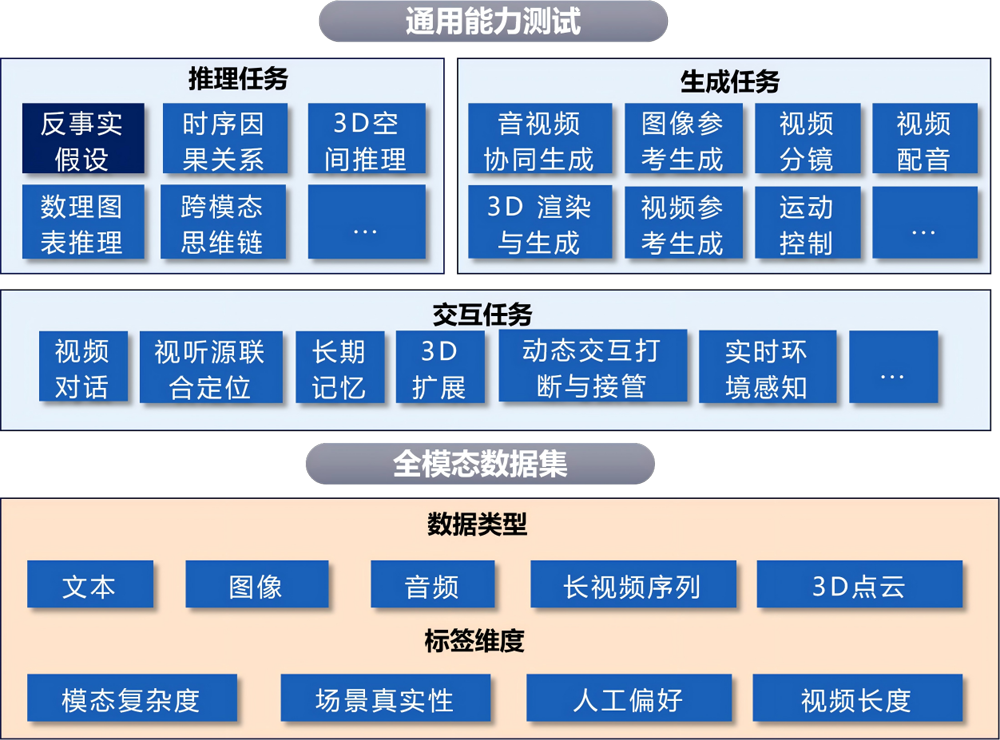
本次评测聚焦全模态大模型的反事实推理能力,要求模型在融合文本、音频与视频信息的基础上,完成假设性因果推理任务。这类推理是人类认知与决策的核心能力,对大模型而言,不仅需要识别并理解多模态内容,更要求其能够针对与事实相悖的假设情境进行推演。反事实推理测试数据围绕音视频构建,兼容多模态组合,涵盖多种视频时长。题库经多轮人工核验,保障答案客观唯一、评测严谨可靠。
二、测试结果
1.整体测试结果
评测模型包含闭源大模型、开源全模态大模型以及音频-视觉大语言模型,整体测试结果如下:
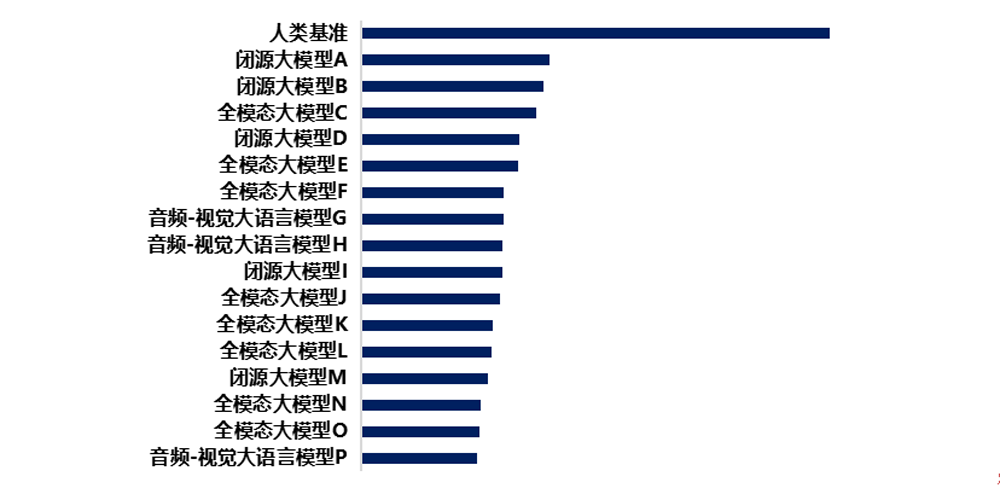
测试结果显示,一是人类基准大幅领先,人类回答平均准确率远超被测大模型。二是开源模型与闭源模型之间仍存明显差距,闭源大模型平均准确率高于开源全模态大模型。三是部分音频-视觉大语言模型表现靠后,说明单纯依赖音频-视觉融合训练难以实现高质量的反事实推理,而全模态联合预训练展现出优势。
2.细粒度场景推理
场景层面聚焦艺术、体育、科学等十大领域开展评测,测试结果如下:
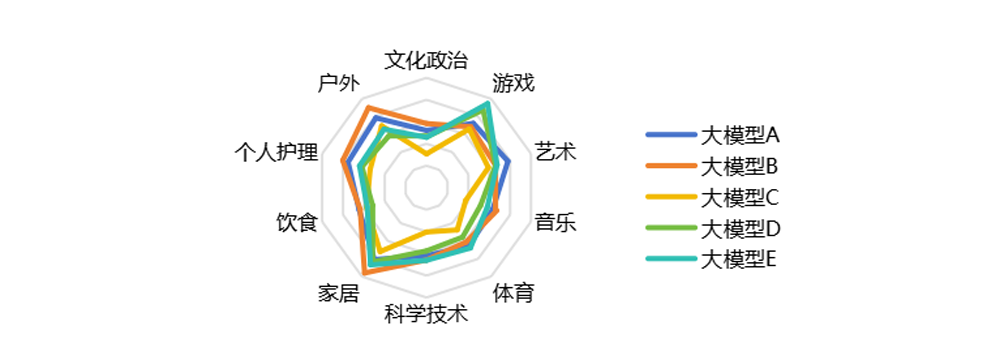
通过测试结果发现,各模型的场景能力呈现分化:在家居、个人护理等生活化场景中,模型表现普遍更优;而在文化政治、科学技术等专业知识领域,以及体育、音乐等需要复杂逻辑与时序理解的场景中,模型在跨领域知识融合与复杂因果推理上仍存在不足。
3.多模态输入形式对比
测试对比模态输入信息对模型推理的影响,测试结果如下:
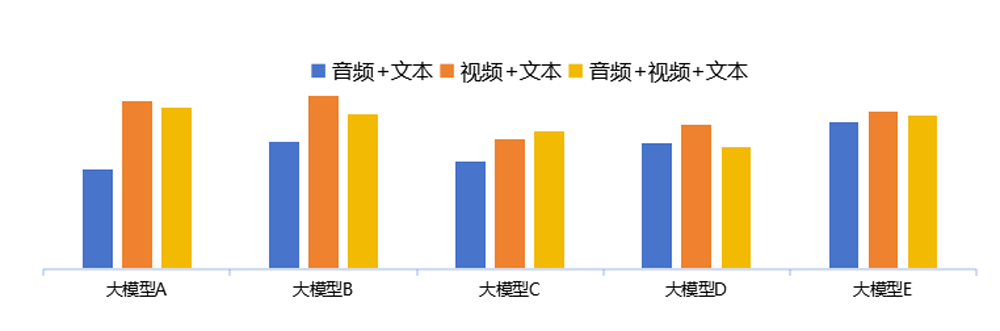
通过测试结果发现,模型对不同模态输入形式的有效性存在差异:一是音频信息辅助能力有限,“音频 + 文本”输入下模型准确率普遍最低,纯音频难以提供足够的场景与时序细节支撑;二是视觉信息对反事实推理起到关键作用,参评模型在“视频 + 文本”输入下准确率较高,说明时序视觉信息是构建因果链条的核心支撑;三是多模态融合尚未实现有效协同,大部分模型在“音频 + 视频 + 文本”全模态输入下无法达到最佳表现,反映出当前模型的跨模态融合能力仍存短板,未实现全模态的协同增益。
下一步重点方向
后续,中国信通院将联合各界专家学者深入关注全模态大模型的推理、生成及动态交互能力,开展相关基准测试标准研制和全模态数据建设,推动全模态生态健康发展。“方升”基准测试将顺应技术和产业发展需要,持续迭代更新。
编辑:侯智